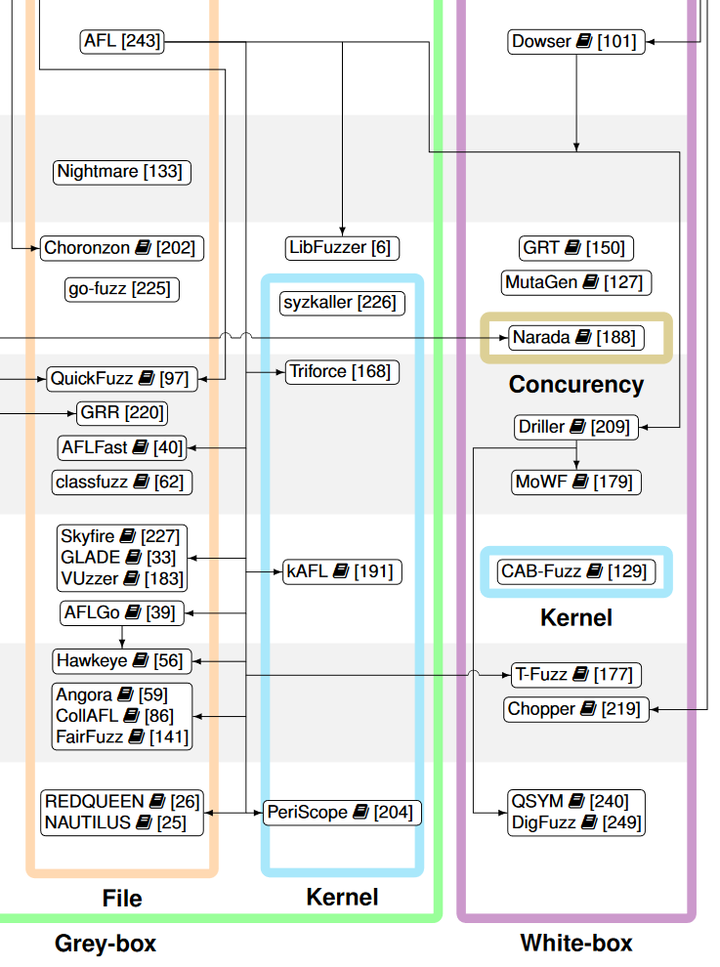
 Fuzzers' Genealogy
Fuzzers' Genealogy
Among the many software testing techniques available today, fuzzing has remained highly popular due to its conceptual simplicity, its low barrier to deployment, and its vast amount of empirical evidence in discovering real-world software vulnerabilities. At a high level, fuzzing refers to a process of repeatedly running a program with generated inputs that may be syntactically or semantically malformed.
Our survey shows the fuzzing community is extremely vibrant. The recent surge of work by researchers and practitioners alike has made it difficult to gain a comprehensive and coherent view of fuzzing. Thus, it is easy to lose track of the design decisions and potentially important tweaks performed in each tool and paper. Furthermore, there has been an observable fragmentation in the terminology used by various fuzzers. For example, test case “minimization” and “reduction” are often used interchangeably. Such fragmentation makes it difficult to discover and disseminate knowledge and may severely hinder the progress in fuzzing research in the long run.
To help preserve and bring coherence to the vast literature of fuzzing, this paper presented a unified, general-purpose model of fuzzing together with a taxonomy of the current literature. Our terminology is chosen to closely reflect the current predominant usages, and our model is designed to suit a large number of fuzzing tasks. We surveyed academic papers from the major Security and Software Engineering conferences in the last 10 years, as well as projects having more than 100 stars on GitHub. The paper methodically explores the design decisions at every stage of the model by surveying the related literature and innovations that make modern-day fuzzers effective.
Companion Website
Our contribution in this work is more than just the survey. Upon receiving the acceptance notice, we have started building a companion website. It is backed by a repository at GitHub, which contains the genealogy and the classification data of the surveyed fuzzers in the JSON format. We plan to keep this site up-to-date periodically through investing our own effort and accepting contributions from the community.